Summary: The error Exchange Database Availability Group Cluster service terminated (Error Code 7024) may occur due to various reasons. In this post, we’ll discuss the possible solutions to fix this error. We’ll also mention an Exchange repair software that can help fix the issue if it occurred due to corrupt database.


In Exchange Server with high availability setup, you may encounter an error – Exchange DAG service terminated with error code 7024. This may stop the users from accessing their data. When you investigate the issue, you might find out that the databases in Exchange Server are not mounted. In such a case, you will start mounting the databases, but the databases may fail to mount, even the public folder databases. In the services management console, you will see that the Cluster Service is also stopped. Any attempts to start the service will be useless. In the Event Viewer, under the System log, you will notice a similar error as given below.
Log Name: System
Source: Service Control Manager
Date: 1/1/2023 12:07:44 AM
Event ID: 7024
Task Category: None
Level: Error
Keywords: Classic
User: N/A
Computer: EX01.mycompany.lan
Description: The Cluster Service service terminated with service-specific error Log service encountered an invalid log block..


The error message doesn’t say much. However, when you dig deeper in the log, you might see a critical error on the Quorum Manager.
Log Name: System
Source: Microsoft-Windows-FailoverClustering
Date: 1/1/2023 12:00:43 AM
Event ID: 1177
Task Category: Quorum Manager
Level: Critical
Keywords:
User: SYSTEM
Computer: EX01.mycompany.lan
Description: The Cluster service is shutting down because quorum was lost. This could be due to the loss of network connectivity between some or all nodes in the cluster, or a failover of the witness disk. Run the Validate a Configuration wizard to check your network configuration. If the condition persists, check for hardware or software errors related to the network adapter. Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
In addition, you might find other messages, such as:
Log Name: System
Source: Microsoft-Windows-FailoverClustering
Date: 1/1/2023 12:00:43 AM
Event ID: 1135
Task Category: Node Mgr
Level: Critical
Keywords:
User: SYSTEM
Computer: EX02.mycompany.lan
Description: Cluster node 'EX02' was removed from the active failover cluster membership. The Cluster service on this node may have stopped. This could also be due to the node having lost communication with other active nodes in the failover cluster. Run the Validate a Configuration wizard to check your network configuration. If the condition persists, check for hardware or software errors related to the network adapters on this node. Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
The above messages indicate that the cluster has failed and both DAG members in the clusters went offline. You can also see that the reason for the failure could be a network issue between the servers.
Solutions to Resolve the Exchange DAG Service Terminated Error
You need to keep in mind that if half plus one nodes fail, the cluster will automatically go in shutdown state to prevent any corruption. This is by design to protect the integrity of the servers and data.
Apart from trying to restore the services, there are a few troubleshooting procedures that you can perform.
The error message indicates issues with network. Therefore, you need to make sure that there weren’t any disconnections on the server or any configuration issue on the VLAN or other network devices, which could have hindered the connectivity between the two servers over the network or the heartbeat network.
It is important to keep a change management log of all the changes as you can always trace back to see what changed from when the servers were working to when they failed.
Another thing to check is the cluster database BLF file. This file contains the metadata of the cluster, which is used to manage access to the log data. It might happen that the CLUSDB.BLF file is corrupted. In this case, you can do the following:
- Browse to the %WinDir%\Cluster folder.
- Rename the CLUSDB.BLF file to something else.
- Restart the Exchange Server services.
The cluster service will recreate the file. Check the service of the cluster and confirm that it’s running. Then, try to mount the databases via the Exchange Admin Center (EAC).
In case of power failure or hardware issue, the data gets corrupted. You can run the ESEUtil on the affected server using the /mh parameter to check the state of the database. If it is in the Dirty Shutdown state, it means that the database is corrupted.

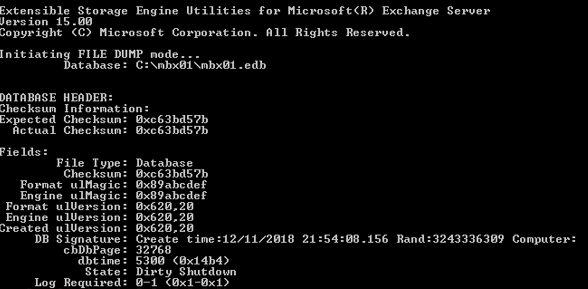
In this case, you need to perform soft recovery or hard recovery, if necessary.

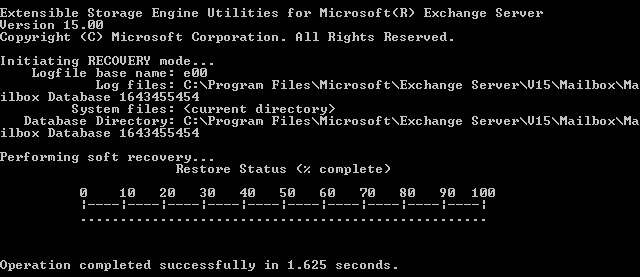
The soft recovery will try to fix the small corrupted items in the database. If you run the hard recovery, you need to accept data loss as it simply purges anything which is deemed as corrupted. Also, there is no guarantee that the databases will mount after hard recovery.


The Alternative Solution
Alternatively, you can use a third-party software, such as Stellar Repair for Exchange to quickly recover from such situations. With this software, you can open multiple EDB files – be it healthy or not – from any Exchange Server version. You can browse through the data store and granularly export to PST and other file formats with ease. You can also use the application to export the EDB data directly to Microsoft 365 or a new live Exchange Server database. The software comes with features, such as automatic mailbox matching, parallel exports, priority export, and continuation in case of interruption.

